Базы данных
Принципы построения баз данных
Всегда, когда возникает потребность манипулировать большими массивами данных, используются базы данных. Работа с базами данных в C++Builder — это столь обширная тема, что ей надо было бы посвящать отдельную книгу объемом не меньшую, чем та, которую вы сейчас читаете. Поэтому в рамках данной книги мы вынуждены будем рассмотреть только основы создания приложений для работы с базами данных. Впрочем, этого будет достаточно для того, чтобы строить достаточно мощные и полезные приложения.
Допуская, что читатели неплохо знакомы с принципами построения баз данных, мы, тем не менее, очень коротко рассмотрим здесь эти принципы, чтобы в дальнейшем использовать единую и понятную всем терминологию.
База данных — (мы будем говорить о так называемых реляционных базах данных) это, прежде всего набор таблиц, хотя, как мы увидим позднее, в базу данных могут входить также процедуры и ряд других объектов. Таблицу можно представлять себе как обычную двумерную таблицу с характеристиками (атрибутами) какого-то множества объектов. Таблица имеет имя — идентификатор, по которому на нее можно сослаться. В табл. 9.1 приведен пример фрагмента подобной таблицы с именем Pers, содержащей сведения о сотрудниках некоторой организации. Эта таблица будет в дальнейшем использоваться в примерах по работе с базами данных. Вы можете найти ее на диске, приложенном к книге, или построить сами при изучении материала раздела 9.2.Столбцы таблицы соответствуют тем или иным характеристикам объектов — полям. Каждое поле характеризуется именем и типом хранящихся данных. Имя поля - это идентификатор, который используется в различных программах для манипуляции данными. Он строится по тем же правилам, как любой идентификатор, т.е. пишется латинскими буквами, состоит из одного слова и т.д. Таким образом, имя — это не то, что отображается на экране или в отчете в заголовке столбца (а отображение естественно писать по-русски), а идентификатор, соответствуют этому заголовку. Например, для таблицы 9.1 введем для последующих ссылок имена полей Num, Dep, Fam, Nam, Par, Year_b, Sex, Charact, Photo, соответствующие указанным в ней заголовкам полей.
Тип поля характеризует тип хранящихся в поле данных. Это могут быть строки, числа, булевы значения, большие тексты (например, характеристики сотрудников), изображения (фотографии сотрудников) и т.п.
Каждая строка таблицы соответствует одному из объектов. Она называется записью и содержит значения всех полей, характеризующие данный объект.
При
построении таблиц баз данных важно
обеспечивать непротиворечивость
информации. Обычно это делается
введением ключевых полей —
обеспечивающих уникальность каждой
записи. Ключевым может быть одно или
несколько полей. В приведенном выше
примере можно было бы сделать
ключевыми совокупность полей
Fam, Nam и
Par.
Но в этом случае нельзя было бы
заносить в таблицу сведения о полных
однофамильцах, у которых совпадают
фамилия, имя и отчество. Поэтому в
таблицу введено первое поле
Num — номер, которое можно сделать
ключевым, обеспечивающим уникальность
каждой записи.
При работе с таблицей пользователь или программа как бы скользит курсором по записям. В каждый момент времени есть некоторая текущая запись, с которой ведется работа. Записи в таблице базы данных физически могут располагаться без какого-либо порядка, просто в последовательности их ввода (появления новых сотрудников). Но когда данные таблицы предъявляются пользователю, они должны быть упорядочены. Пользователь может хотеть просматривать их в алфавитном порядке, или рассортированными по отделам, или по мере нарастания года рождения и т.п. Для упорядочивания данных используется понятие индекса. Индекс показывает, в какой последовательности желательно просматривать таблицу. Индекс является как бы посредником между пользователем и таблицей (см. рис. 9.1).
Курсор скользит по индексу, а индекс указывает на ту или иную запись таблицы. Для пользователя таблица выглядит упорядоченной, причем он может сменить индекс и последовательность просматриваемых записей изменится. Но в действительности это не связано с какой-то перестройкой самой таблицы и с физическим перемещением в ней записей. Меняется только индекс, т.е. последовательность ссылок на записи. Индексы могут быть первичными и вторичными. Например, первичным индексом могут служить поля, отмеченные при создании базы данных как ключевые, вторичные индексы могут создаваться из других полей как в процессе создания моей базы данных, так и позднее в процессе работы с ней. Вторичным индексам присваиваются имена — идентификаторы, по которым их можно использовать.
Если индекс включает в себя несколько полей, то упорядочивание базы данных сначала осуществляется по первому полю, а для записей, имеющих одинаковые значения первого поля — по второму и т.д. Например, базу данных Pers можно индексировать по отделам, а внутри каждого отдела — по алфавиту.
База данных обычно содержит не одну, а множество таблиц. Например, база данных о некоторой организации может содержать таблицу имеющихся в ней подразделений с характеристикой каждого из них. Пример такой таблицы с именем Pers, которая будет использоваться нами в дальнейшем, приведен в таблице 9.2. Имена полей этой таблицы, которые в дальнейшем мы будем использовать: Dep и Proisv.
Отдельные таблицы, конечно, полезны, но гораздо больше информации можно извлечь именно из совокупности таблиц. Например, пользователю может требоваться узнать общее количество сотрудников, работающих в производственных цехах. Но ни одна из приведенных выше таблиц не поможет ответить на этот вопрос, поскольку в таблице Pers отсутствуют сведения о типах отделов, а в таблице Dep — о сотрудниках. Для получения ответов на подобные запросы необходимо рассмотрение совокупности связных таблиц.
В связных таблицах обычно одна выступает как главная, а другая или несколько других — как вспомогательные, управляемые главной. В этом случае взаимодействие таблиц иллюстрируется рисунком 9.2. Главная и вспомогательная таблицы связываются друг с другом ключом. В качестве ключа могут выступать какое-то поля, присутствующие в обеих таблицах. Например, в приведенных ранее таблицах головной может быть таблица Dep, вспомогательной Pers, а связываться они могут по полю Dep, присутствующему в обеих таблицах. Курсор скользит по индексу главной таблицы. Каждой записи в главной таблице ключ ставит в соответствие в общем случае множество записей вспомогательной таблицы. Так в нашем примере каждой записи главной таблицы Dep соответствуют те записи вспомогательной таблицы Pers, в которых ключевое поле Dep с названием отдела совпадает с названием отдела в текущей записи главной таблицы. Иначе говоря, если в текущей записи главной таблицы в поле Dep написано «Бухгалтерия», то во вспомогательной таблице Pers выделяются все записи сотрудников бухгалтерии.
Создают базы данных и обрабатывают запросы к ним системы управления данных — СУБД. Известно множество СУБД, различающихся своими возможностями или обладающих примерно равными возможностями и конкурирующих друг с другом: Paradox, dBase, Microsoft Access, FoxPro, Oracle, InterBasiase и много других. '
Разные СУБД по-разному организуют и хранят базы данных. Например, Paradox и dBase используют для каждой таблицы отдельный файл. В этом случае база данных — это каталог, в котором хранятся файлы таблиц. В Microsoft Access, InterBase несколько таблиц хранится как один файл. В этом случае база данных — это имя файла с путем доступа к нему. Системы типа клиент/сервер, такие как серверы Sybase или Microsoft SQL, хранят все данные на отдельном компьютере и общаются с клиентом посредством специального языка, называемого SQL (см. Раздел 10.1). Поскольку конкретные свойства баз данных очень разнообразны, пользователям было бы весьма затруднительно работать, если бы он должен был указывать в своем приложении все эти каталоги, файлы, серверы и т.п. Да и приложение часто пришлось бы переделывать при смене, например, структуры каталогов и при переходе с одного компьютера на другой. Чтобы решить эту проблему, используют псевдонимы баз данных. Псевдоним (alias) содержит всю информацию, необходимую для обеспечения доступа к базе данных. Эта информация сообщается только один раз при создании псевдонима. А приложение для связи с базой данных использует псевдоним. В этом случае приложению безразлично, где физически расположена та или иная база данных, а часто безразлична и СУБД, создавшая и обслуживающая эту базу данных. При смене системы каталогов, сервера и т.п. ничего в приложении переделывать не надо. Достаточно, чтобы администратор базы данных ввел соответствующую информацию в псевдоним.
При работе с базами данных часто используется кэширование всех изменений. Это означает, что все изменения данных, вставка новых записей, удаление существующих записей, т.е. все манипуляции с данными, проводимые пользователем, сначала делаются не в самой базе данных, а запоминаются в памяти во временной, виртуальной таблице. И только по особой команде после всех проверок правильности вносимых в таблицу данных пользователю предоставляется возможность или фиксировать все эти изменения в базе данных, или отказаться от этого и вернуться к тому состоянию, которое было до начала редактирования.
Фиксация изменений в базе данных осуществляется с помощью транзакции. Это совокупность команд, изменяющих базу данных. На протяжении транзакции пользователь может что-то изменять в данных, но это только видимость. В действительности все изменения сохраняются в памяти. И пользователю предоставляется возможность завершить транзакцию или внесением всех изменения в реальную базу данных, или отказом от этого с возвратом к тому состоянию, которое было до начала транзакции.
1.2 Типы баз данных
Для разных задач целесообразно использовать различные модели баз данных поскольку, конечно, базу данных сведений о сотрудниках какого-то небольшого коллектива и базу данных о каком-нибудь банке, имеющем филиалы во всех странах мира, надо строить по-разному.
Процесс определения того, какая база данных более подходит для конкретного приложения, называется масштабированием. Это сложная задача, которую будем затрагивать. Однако прежде чем двигаться дальше, необходимо представление о возможных моделях баз данных, поскольку это влияет строение приложений в C++Builder. В следующих разделах коротко рассмотрены четыре модели баз данных:
- Автономные;
- Файл - серверные;
- Клиент / сервер;
- Многоярусные.
Прежде, чем переходить к рассмотрению различных моделей баз данных, отметим, что работа с данными в C++Builder в основном осуществляется через Borland Database Engine (BDE) — процессор баз данных фирмы Borland. Соответствующая программа должна быть поставлена на компьютере пользователя во всех моделях баз данных, кроме многоярусных.
9.1.2.1 Автономные базы данных
Автономные локальные базы данных являются наиболее простыми. Они хранят свои данные в локальной файловой системе на том компьютере, на котором установлены; система управления и машина базы данных, осуществляющая к ним доступ, находится на том же самом компьютере. Сеть не используется. Поэтому разработчику автономной базы данных не приходится иметь дело с проблемой параллельного доступа, когда два человека пытаются одновременно изменить одну и ту же запись, потому что такого никогда не может быть. Вообще, автономные базы данных не используются для приложений, требующих значительной вычислительной мощности, потому что процессорное время будет потрачено на выполнение манипуляций с данными и в целом будет потеряно для приложения.
Автономные базы данных полезны для развития тех приложений, которые распространены среди многих пользователей, каждый из которых поддерживает отдельную базу данных. Это, например, приложения, обрабатывающие документацию небольшого офиса, кадровый состав небольшого предприятия, бухгалтерские документы небольшой бухгалтерии. Каждый пользователь такого приложения манипулирует своими собственными данными на своем компьютере. Пользователю нет необходимости иметь доступ к данным любого другого пользователя, так что отдельная база данных здесь вполне приемлема.
9.1.2.2 Файл - серверные базы данных
Файл - серверные базы данных отличаются от автономных тем, что они могут быть доступны многим клиентам через сеть. Это очень удобно, так как изменения в таких базах данных видят все пользователи. Например, базу данных сотрудников крупного учреждения целесообразно делать именно такой, чтобы администраторы отдельных подразделений обращались к ней, а не заводили у себя локальные базы данных (при этом можно сделать так, чтобы каждый администратор видел только ту информацию, которая относится к его подразделению).
Сама база данных хранится на сетевом файл-сервере в единственном экземпляре, но для каждого клиента во время работы создается локальная копия данных, с которой он работает. При этом возникают (и решаются) проблемы, связанные с одновременным доступом нескольких пользователей к одной и той же базе данных. Например, при проектировании приложений, работающих с сетевыми базами данных, должны быть решены такие проблемы: что делать, если пользователь прочел некоторую запись и, пока он ее просматривает и собирается изменить, другой пользователь меняет или удаляет эту запись. Из остатков баз данных файл-сервер является непроизводительной. При каждом запросе клиента данные в его локальной копии полностью обновляются из базы данных на сервере. Даже если запрос относится всего к одной записи, обновляются все записи данных. Если записей в базе данных много, что при небольшом числе клиентов сеть будет загружена очень основательно.
Другой недостаток связан с тем, что забота о целостности данных при такой организации работы возлагается на программы клиентов. Если они недостаточно тщательно продуманы, в базу данных легко занести ошибки, которые могут отразиться на всех пользователях.
9.1.2.3 Базы данных клиент/сервер
Для больших баз данных с множеством пользователей часто использую базы данных на платформе клиент/сервер. В этом случае доступ к базе данных для группы клиентов выполняется специальным компьютером — сервером, или дает задание серверу выполнить те или иные операции поиска или обновления базы данных. И мощный сервер, ориентированный на операции с запросами, оптимальным способом, выполняет их и сообщает клиенту результаты своей работы.
Подобная организация работы повышает эффективность выполнения приложений за счет использования мощности сервера, разгружает сеть, обеспечивает хороший контроль целостности данных.
В базах данных клиент/сервер возникает дополнительная проблема — спроектировать приложение так, чтобы оно максимально использовало возможности сервера и минимально нагружало сеть, передавая через нее только минимум информации.
9.1.2.4 Многоярусные базы данных
Это новый и многообещающий путь обработки данных в сети. Иногда (в частности, в документации C++Builder) этот способ организации баз данных называется multi - tier — много нитевые. В этом термине под нитью понимается один из множества потоков данных, обменивающихся одновременно с базой данных.
Наиболее распространен трехъярусный вариант:
• На нижнем уровне на компьютерах пользователя расположены приложения клиентов, обеспечивающие пользовательский интерфейс.
• На втором уровне расположен сервер приложений, обеспечивающий обмен данными между пользователями и распределенными базами данных. Сервер приложений размещается в узле сети, доступном всем клиентам.
• На третьем уровне расположен
удаленный сервер баз данных,
принимающий информацию от серверов
приложений и управляющий ими. Подобную
концепцию обработки данных
пропагандируют, в частности, фирмы Oracle и Sun.
Первый, элементарный уровень состоит из “тонких клиентов”, сеть несложных терминалов, предназначенных, в основном, для ввода — вывода.
Второй, средний (middleware) уровень — это рабочие станции и серверы приложений, то есть значительно более серьезные машины, на которых выполняются программы, критичные к загрузке процессора.
Третий и последний уровень специализированные серверы баз данных.
Отметим одну особенность многоярусных распределенных баз данных, на нижнем уровне — на компьютерах пользователя не требуется установка Borland Database Engine (BDE). В этом заключается одно из преимуществ такой организации баз данных.
9.1.3 Технологии СОМ и CORBA
Для создания распределенных СУБД в настоящее время используются в основном две технологии: СОМ и CORBA. Кроме того, в связи с бурным развитием Internet, все большее значение приобретает технология Web, которая, возможно в будущем станет определяющей.
В рамках данной книги распределенные СУБД рассматриваться не будут. Соответственно не будут рассматриваться и связанные с построением таких баз данных компоненты Provider, ClientDataSet, RemoteServer и др. Тем не менее, ниже приведены некоторые основные понятия, связанные с созданием распределенных придаются поскольку без этого картина организации работы с базами данных была бы неполной.
технология СОМ (компонентная модель объекта) разработана корпорацией soft. Ее назначение — предоставление возможности одной программе (клиенту) работать с объектом другой программы (сервера). СОМ - это модель объекта, которая предусматривает полную совместимость во взаимодействии между компонентами, написанными разными компаниями и на разных языках. При этом клиент и сервер могут располагаться на разных компьютерах. В СОМ основаны такие технологии Microsoft, как OLE, Automation OLE, aktiveX OCX. На СОМ построен, например, весь интерфейс Windows 98.
СОМ определяет унифицированный двоичный интерфейс, полностью независимый от языка программирования, использованного при реализации компонен-Компонент, написанный в соответствии со спецификациями двоичного интерфейса СОМ, может вступать во взаимодействие с другим компонентом, не зная в действительности ничего о реализации последнего.
Каждый интерфейс имеет уникальный идентификатор IID (Interface Identifier), являющийся частным случаем GUID (Global Unique Identifier) — глобального идентификатора, используемого в Windows. Параметры интерфейса описывают некоторый класс с идентификатором CLSID (Class ID), в котором объявлены поля, свойства, методы, параметры обращения к свойствам и методам. Таким образом, клиент с помощью этого интерфейса может использовать объект СОМ сервера так же, как свой собственный объект. Любой объект СОМ имеет интерфейс Unknown, с помощью которого получает доступ к основному интерфейсу объекта.
Сервер СОМ реализуется в виде программы или DLL. Если клиент и сервер располагаются на разных компьютерах, используется распределенный вариант СОМ — DCOM. При этом обмен информацией между клиентом и сервером осуществляется двумя промежуточными программами: Proxy (уполномоченный) и Stub (заглушка). Proxy располагается на машине клиента. Получив от клиента запрос, Proxy упаковывает его в пакет СОМ и переправляет на машину сервера. Там этот пакет перехватывает Stub, распаковывает пакет и передает запрос серверу. Таким образом, запрос выполняется на машине сервера.
CORBA (Common Object Request Broker Architecture) — это стандарт построения приложений с распределенными объектами. Разработчиком CORBA является отраслевой комитет OMG (Object Management Group — группа управления объектами), представляющий многие фирмы. Взаимодействие клиента и сервера в Stub осуществляется через ряд посредников. На машине клиента размещается брокер (Object Require Broker). Клиент обращается к Stub так, как если бы это был сам объект. При этом используется интерфейс объекта, предоставляемый клиенту с помощью Stub.
ORB транслирует полученный от клиента вызов какого-то метода объекту ентап тот ^Р6'4^'!' соответствующее сообщение в сеть. В сетевом окружении кли-"ереда^110''1211^10^" ооъекты Smart компилятором позволяет делать обмен Agent (интеллектуальные агенты). Сообщение, ^й ал ное o®ъeктoм ORB, перехватывает один из Smart Agent, отыскивает сете-^Рвепя ccooтвeтcтвУЮЩeгo сервера и передает полученное сообщение на машину О^В о ^шине сервера сообщение воспринимает расположенный там объект ^зовый ^Р^^'1' бго расположенному там же объекту BOA (Basic Object Adapter -Js!isl' Ka ^^'^P объекта). BOA может проводить фильтрацию запросов, опреде-Рабатьтп ои ^"Вбнь доступа разрешен данному клиенту и вообще разрешено ли об-^'Зов в ть такои ^прос данного клиента. Если доступ разрешен, то BOA передает "ообый объект сервера — Skeleton, который и реализует сам вызов.
Интерфейс в CORBA описывается с помощью специального языка IDL (Interface Definition Language), напоминающего C++. Компилятор IDL создает в процессе компиляции объекты Stub и Skeleton данного интерфейса. Использование языка высокого уровня в сочетании с данными независимыми от аппаратных средств. Поэтому клиент и сервер могут располагаться на машинах разных платформ, например, на персональном компьютере IBM и рабочей станции Sun.
При обмене информацией между ORB и Smart Agent используется протокол UDP. Для реализации CORBA в сетевом окружении клиента должен существовать хотя бы один объект Smart Agent. Обычно в локальной сети Smart Agent располагается на головной машине, а в Интернете — на одном из узлов. При создании сервера он регистрируется в Smart Agent. Таким образом, Smart Agent знает, где найти тот или иной сервер, а при отказе одного сервера может переключиться на другой. Это повышает надежность работы.
9.1.4 Организация связи с базами данных в C++Builder
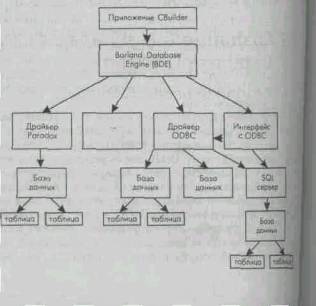
Основой работы C++Builder с базами данных является Borland Database Engine (BDE) — процессор баз данных фирмы Borland. BDE служит посредником между приложением и базами данных. Он предоставляет пользователю единый интерфейс для работы, развязывающий пользователя от конкретной реализации базы данных. Благодаря этому не надо менять приложение при смене реализации базы данных. Приложение C++Builder никогда не обращается непосредственно к базе данных, а только к BDE. Таким образом, общение с базами данных соответствует схеме, приведенной на рис. 9.3.
Приложение C++Builder, когда ему нужно связаться с базой данных, обращается к BDE и сообщает обычно псевдоним базы данных и необходимую таблицу в ней, BDE реализован в виде динамически присоединяемых библиотек DLL (файлы IDAPI01.DLL, IDAPI32.DLL). Они, как и любые библиотеки, снабжены API (Application Program Interface — интерфейсом прикладных программ), названным IDAPI (Integrated Database Application Program Interface). Это список процедур и функций для работы с базами данных, которым и пользуются приложения.
BDE по псевдониму находит подходящий для указанной базы данных драйвер. Драйвер — это вспомогательная программа, которая понимает, как общаться с базами данных определенного типа. Если в BDE имеется собственный драйвер соответствующей СУБД,
|
|
Рис. 9.3.
Схемо связи приложения C++Builder с бозоми данных
то BDE связывается через него с базой данных и с нужной таблицей в ней, обрабатывает запрос пользователя и возвращает в приложение результаты обработки. BDE поддерживает естественный доступ к таким базам данных, как Microsoft Access, FoxPro, Paradox, dBase.
Если собственного драйвера нужной СУБД в BDE нет, то используется драйвер ODBC. ODBC (Open Database Connectivity) — это DLL, аналогичная по функциям BDE, но разработанная фирмой Microsoft. Она хранится в файле ODBC. DLL. Поскольку Microsoft включила поддержку ODBC в свои офисные продукты и для ODBC созданы драйверы практически к любым СУБД, фирма Borland включила в BDE драйвер, позволяющий использовать ODBC. Правда, работа через ODBC осуществляется несколько медленнее, чем через собственные драйверы СУБД, включенные в BDE. Но благодаря связи с ODBC масштабируемость C++Builder существенно увеличилась и сейчас из C++Builder можно работать с любой сколько-нибудь значительной СУБД.
BDE поддерживает SQL — стандартизованный язык запросов, позволяющий обмениваться данными с SQL-серверами, такими, как Sybase, Microsoft SQL, Oracle, Interbase. Эта возможность используется особенно широко при работе на платформе клиент/сервер и в распределенных базах данных.
В C++Builder 5 введена другая альтернативная возможность работы с базами данных, минуя BDE. Это разработанная в Microsoft технология ActiveX Data Objects (ADO). ADO - это пользовательский интерфейс к любым типам данных, включая реляционные и не реляционные базы данных, электронную почту, системные, текстовые и графические файлы. Связь с данными осуществляется посредством так называемой технологии OLE DB.
Использование ADO обеспечивает более эффективную работу с данными. Однако надо сказать, что возможности ADO в C++Builder пока в некоторых отношениях ниже, чем возможности BDE. Поэтому в дальнейшем мы в основном сосредоточимся на работе с BDE. А особенности использования ADO будут рассмотрены в главе 10 в разделе 10.4.
Еще один альтернативный доступ к базам данных Interbase введен в C++Builder 5 на основе технологии InterBase Express (IBX). В библиотеке компонентов C++Builder 5 имеется страница InterBase, содержащая компоненты для работы с InterBase, минуя BDE. Эти компоненты обеспечивают повышенную производительность и позволяют использовать новые возможности сервера InterBase, недоступные обычным компонентам BDE. Этот новый вариант связи с базами данных будет рассмотрен в главе 10 в разделе 10.5.
Назад | Содержание | Вперёд